

Most of us realize monitoring technical SEO health is crucial. But, is your audit modern? Are you taking the most important variables TODAY into account? Have you kept up to date as to the best methodology and tools? If the answer is, “No,” then stress is likely for lack of traffic and loot-booty.
In spite of a growing perception that SEO is dead, reality is that SEO issues and opportunities surround us. OLD SEO is dead. Long shall live modern realities. Making sure your SEO audit reflects a current understanding of what SEO is and needs to be is key. You’ll help uncover crucial content, architecture, and indexing problems that can arise over time.
Any site with active content editing or those with ongoing website development changes are particularly prone to problems over time in this day and age.
As always, a modern technical SEO audit is the first step to identifying painful indexing barriers and gaining insight into new opportunities.
The good news is that auditing sites for technical SEO issues and opportunities is easy once you know what to look for. We’ll use a few tools along the way to gather data, but it’s not just about the tools… it’s knowing what to ask the tools. In this article we will outline our process, highlight key questions we’re asking and identify the tools we use to execute a technical SEO audit.
Prior to performing a technical SEO audit, it’s critical to understand the goals and objectives of such a review. The goals of the technical SEO audit are to identify on-page issues and opportunities for a given website. Our objectives are to remove barriers to healthy search indexation and increase data visibility to optimize the technical SEO foundation of the website. As such, we’re looking for unintended code that may block SEO value from propagating through the site, while also assessing the use of various on-page technical elements and identifying opportunities to increase SEO value.
The stress on “technical” means we’re primarily looking at code-level and systems-level SEO touch points as opposed to a “semantic” audit, which would be focused on keyword prevalence in the website content itself, as well as linking constructs. That said, there are inevitable ways in which semantic and technical recommendations will intertwine as we progress through the audit and into the recommendations.
So, let’s dig in. We start our audit with documentation. In fact, the vast majority of the audit process includes gathering and documenting data, which in the end provides us with the basis for the audit recommendations. In a nutshell, our easy, four-step process for executing a technical SEO audit can be broken down as:
- Documenting Traffic History
- Analyzing Indexation
- Reviewing Website Code
- Compiling Recommendations
Step 1: Documenting Traffic History
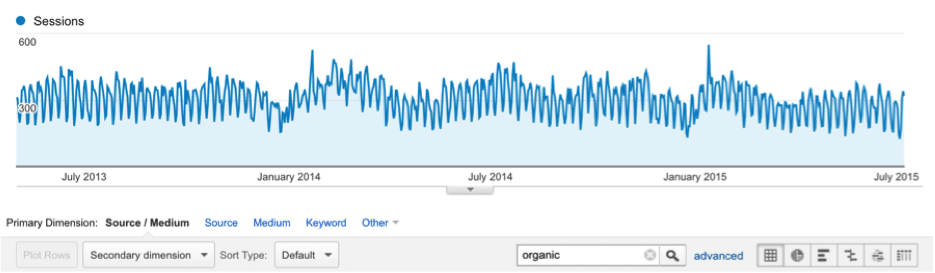
To know where to go, we need to understand where we’ve been. A quick look at overall organic traffic provides a glimpse into the traffic history up to the current point in time. We want to look back as far as we can go— ideally a minimum of one year of history, when possible, to get a feel for the cyclical nature of the business.
Since, in Google Analytics, channel data is not available in Google prior to July 25, 2013, we prefer to go straight to the source data and filter for organic. To do this in GA, go to Acquisition -> All Traffic -> Source/Medium and then in the search box, enter “organic” to view organic traffic history. For example:
Step 2: Analyze Indexation
So, we have traffic and we see some patterns… now what? The next step is to look at the current indexation status. To assess indexation we go to the index itself: Google. Ok, Google isn’t the only index, but it is the most popular in the U.S. and, for us, serves as a benchmark for SEO recommendations. In full disclosure, we prefer to assess both Google Analytics and Bing when resources allow. Regardless of the data source, what we are looking for is the presence of the given domain in the search results and the current makeup of the relevant entries.
We begin by manually reviewing Google’s site indexing. A quick search of “site:domain.com” returns the currently indexed pages for the given domain. Here we’re taking note of the total number of pages indexed while also reviewing and documenting the domain structure for the indexed pages.
For domain structure, we’re reviewing three aspects:
- Is SSL used (http vs. https in the URL)?
- Is www or non-www used, or both?
- What is the page URL hierarchy?
For the first two aspects — SSL and www — not only are we documenting what’s indexed, but we would also perform a manual check to see what the site enforces. For example, if the site is indexed as http://www.domain.com, does it forcefully redirect us to http and/or www if we alternate the values manually as https://domain.com? Or, does it render the same page regardless of entry? What we need to determine here is: Which version(s) are indexed? Which version(s) are enforced by the server? And, which version(s) are preferred or required by the business stakeholders?
For the third aspect — URL hierarchy — we are checking whether inner pages utilize hierarchical folder structures. We classify the site as having either a flat structure or a layered structure. For example:
Flat Structure:Â domain.com/blog-article-title
Layered Structure:Â domain.com/category/blog-article-title
Remember: At this point we are simply documenting. However, all of this will come into play later in the article as we formulate and prioritize our recommendations.
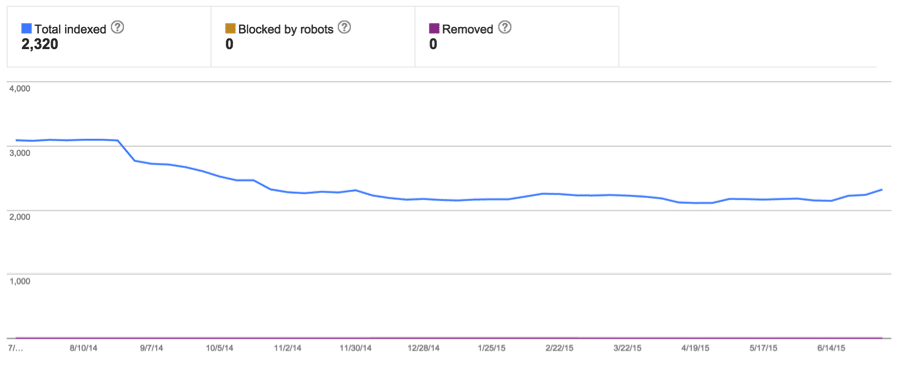
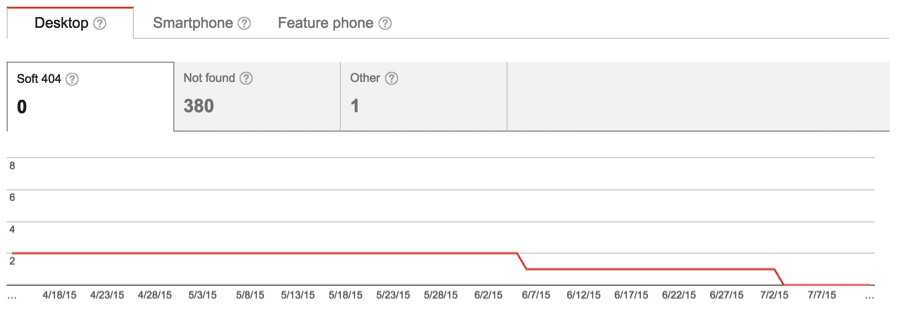
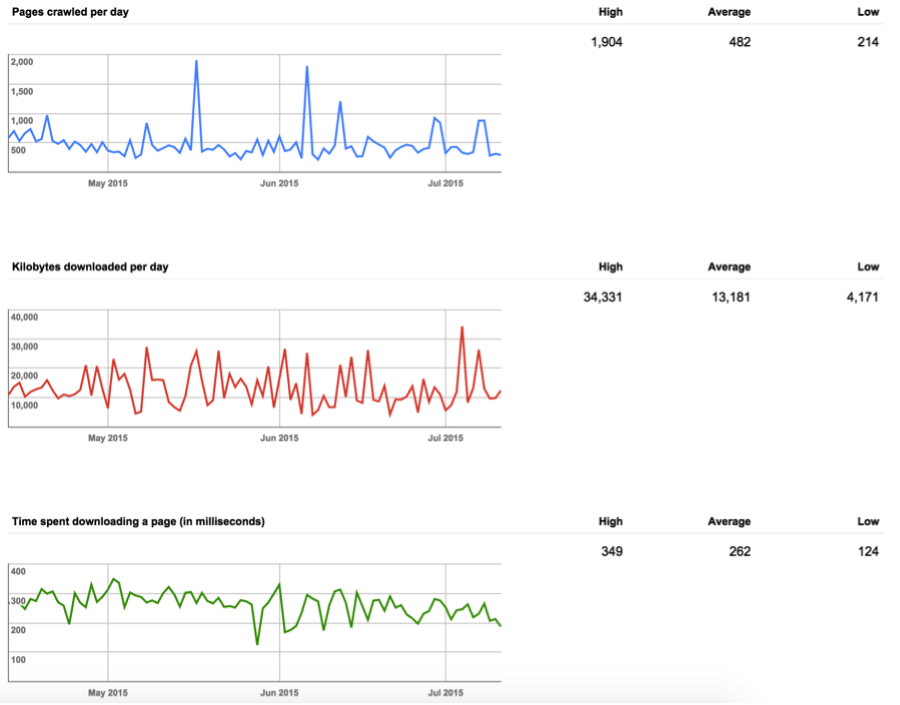
As part of our documentation, we pull indexation graphs from Google Webmaster Tools. This is great because it provides some historic context in addition to a snapshot of the current scenario. The graphs we pull include index status, crawl errors and crawl status. This paints a picture, demonstrating to us how many pages Google has access to and which types of issues they may be having with the given domain.
Index Status
Crawl Errors
Crawl Stats
Step 3: Review Website Code
A manual review of website code is inevitable and embodies the next step of our technical SEO analysis. However, we’re looking for a very specific set of code elements and we get a little help along the way from our trusty toolset. This reduces time spent analyzing code and focuses on the key issues in play.
An outline of the code elements and logic we’re focused on include:
- Code Structure
- CMS detected?
- Code layout appropriate?
- Number of and placement of CSS and JS included?
- Use and placement of inline JS code?
- What is the page load time?
- Is the site responsive and rendering as mobile friendly?
- Analytics
- Present and functioning?
- Robots Directives (robots.txt and meta robots rules)
- Present?
- Any needed pages, URLs, or folders being blocked? (Tip: Run the Google Mobile Friendly check to be sure needed CSS files are not blocked, stunting mobile SEO value.)
- XML Sitemap(s)
- Present? Data up to date and accurate?
- RSS Feeds
- Present? Data up to date and accurate?
- Meta Tags
- Is a title tag used on all pages? Value the same or unique per page?
- Is a meta description tag used on all pages? Value the same or unique per page?
- Is a canonical tag used on all pages? Is value accurate?
- Image Alt Tags
- Are image alt tags used?
- If so, are SEO keywords used?
- Open Graph Tags
- Are Open Graph tags being used?
- If so, are values different per page or global?
- Schema Tags
- Are Schema tags used?
- If so, which?
- Is use appropriate?
- H Tags
- Are H tags used? (ie <h1>,<h2>,<h3>, etc)
- If so, are they nested appropriately?
- Only one <h1> per page
- Use <h2> and <h3> when needed, but only in succession
Several of these we are able to identify quickly by a simple scan of the home page code. However, it’s best practice here to review multiple pages — at least one page for each different type of website page on the given domain. For example, on an ecommerce site, we often review the home page, category page, product page, shopping cart page and a regular content page. If a blog were also included, we’d review the blog roll page and individual blog article pages. We want to be sure we’re documenting the presence of tags across the entire site rather than just the home page.
Determining whether the site is responsive has been a core element of our technical SEO audits for some time. However, in our most modern SEO audit process we’ve extended this further to determine whether a site is truly listed as mobile friendly using the Google Mobile Friendly tool. This is a key addition in recent months as many CMS solutions, including WordPress, default to blocking robots to certain folders which can actually lead Google to flag a responsive website as non-mobile friendly. Identifying any issues that may be preventing Google from properly classifying a responsive site as mobile friendly is critical to the modern audit.
For certain tags, such as H tags and image alt tags, we’re able to get a full picture by using our own crawler. For this we turn to Screaming Frog. This tool allows us to quickly and accurately crawl an entire site and analyze the presence of and values of html elements in a spreadsheet. Additional tools including Moz and BrightEdge are used to scan the site for several other on-page issues, including:
- 5XX Server Errors
- 4XX Errors
- Duplicate Page Content
- Crawl Attempt Errors
- Missing Title or Meta Description Tags
- Title or Meta Description Values Too Long
- Title or Meta Description Too Short
- Temporary Redirects
- Blocked by Robots.txt
- Long URLs
- Thin Content
Step 4: Compile Recommendations
In our final step we review all of the documentation performed during the previous three steps as we compile and prioritize our technical SEO recommendations. Here’s where we have to start making some judgment decisions as to which issues to tackle first and which opportunities warrant attention from a limited set of resources. It’s a bit of an art, but there are some general guidelines to consider.
Tackle barriers first. Barriers are technical code elements that can cause a search engine to either ignore certain elements of the page or skip indexing a page entirely. Key elements to consider in this category are the robots.txt file content, the presence of unwanted robots meta directives (noindex,nofollow), and the sitemap.xml file. If there are issues with any of these three elements, boost that directly to the top of the prioritization list and keep it there. Providing a healthy indexation landscape is priority number one when performing search engine optimization.
A key barrier for the modern SEO audit is incorrect robots.txt rules blocking Google Mobile Friendliness. If the site is mobile responsive but does not pass the mobile friendly test, then review the robots.txt file for any rules that could be blocking Google from indexing CSS or JS files used in the website theme. High priority recommendations should include the adjustment or removal of any robots.txt rule that blocks mobile friendliness yet does not open up the site for unwanted indexation.
A key barrier that is often overlooked is http and www enforcement. This can lead to serious duplicate content issues. The ideal scenario with URLs is to have one true version and all alternate versions permanently redirect to the main version. For many sites this is completely possible and easy, yet under utilized.
For example, suppose we want our site to run https rather than http for optimal SEO — and the business prefers www in the URL. In this scenario, the preferred home page URL would be https://www.domain.com.
Now, going back to the ideal scenario, we would want all of the following to 301 redirect to this preferred URL:
http://www.domain.com
http://domain.com
https://domain.com
This isn’t an absolute requirement. There are other ways to achieve the necessary requirements for healthy SEO. One other good way is via the canonical tag. So, we must assess the URL structure, verify what is in place in the code, understand the options and resources available to make any adjustments, and come up with the best recommendation on the URL changes that may be needed. As best practice, I prefer both scenarios above where all versions 301 redirect to the preferred version AND proper canonical tags are in place. This gives you multiple layers of protection and offers some interesting mixes of flexibility for unique situations.
There is one very important consideration we must still make with the URLs. We should try to match current indexing scenario where possible. For example, if Google currently only indexes the http://www version of all pages, that would be the ideal scenario to stick with, excluding other factors. With that said, there are benefits to switching to https over http even if that means Google will be updating the URLs in their index. The key here is that when we are recommending a change that Google will need to update its index for, we must be sure to implement the proper permanent redirects so that Google properly transfers the SEO value when doing so.
Next, weigh priority on-page issues with priority optimizations — and prioritize accordingly. Priority on-page SEO issues are those that don’t shape indexing but either leave significant SEO value on the table or send severe unwanted signals to search engines. Priority on-page issues often include:
- Fix 4XX Errors
- Research and Fix 5XX Server Errors
- Research and Fix Crawl Attempt Errors
- Adjust robots.txt Rules
- Add Missing Title or Meta Description Tags
Priority optimizations are those which can provide significant SEO value once implemented, yet typically are easy — or at least practical — to implement for most customers. Priority optimizations often include:
- Add/Update Sitemap.xml
- Remove Duplicate Page Content
- Add Open Graph Tags
- Add Schema Tags
Finally, prioritize the remaining issues and recommendations according to difficulty. The thought process here is that we want to get through as much as we can, as quickly as we can. So, if two items are similar in value, we want to move forward with the easier one first to get improvements in place as quickly as possible while preventing us from getting too bogged down in the types of optimizations that can be very labor intensive. Remaining issues and optimizations often include:
- Replacing Temporary Redirects
- Shortening Long Meta Tag Values (title and meta description)
- Lengthening Short Meta Tag Values (title and meta description)
- Implementing Semantic Optimizations for Meta Tags, Image Alt Tags, and H Tags
- Adjusting Code Include Positioning
- Minifying Code
Now that your prioritized list is ready, the final action is to summarize your findings. That’s it! With this you’ve now completed a technical SEO audit with prioritized recommendations and are ready to confidently proceed with implementing the recommendations.
Some tasks within the audit should be repeated on a maintenance schedule. Initially, the following should be followed up on daily until resolved for the first batch of reported URLs:
- 5XX Server Errors
- 4XX Errors
- Duplicate Page Content
- Crawl Attempt Errors
Once the first set of issues is resolved, then monitor these weekly to stay on top of new issues going forward. For many sites, regular maintenance is required to correct new 404 Error issues or duplicate content problems. Often this is due to poor URL management by the CMS or due to changes by content editors themselves. Understanding how your CMS handles page URLs when you change the page title and educating content editors on the importance of redirecting old URLs when a URL changes are key steps to reducing the amount of SEO maintenance work required on an ongoing basis. Still, as a safeguard, monitoring your webmaster tools accounts on a regular basis will ensure that you retain SEO value and maintain a healthy, search optimized website.








